昨天提到 DeepFM ,是一個 Deep&Wide 的變型,但本質上仍是兩個網路的合併。那是否有一個深度學習的架構,不用做合併,又可以解決廣度和深度的問題呢?
NFM(Neural Factorization Machines)就是一個這樣的架構。它就是一體成型,不需要再做合併。在訓練上也不必分開訓練,在訓練上變得簡單很多。
原始的 FM 公式是
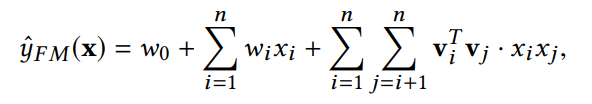
若後面二階交叉項我們把它用另一個函數取代,就可以改寫成
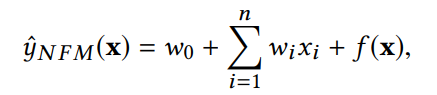
因為深度學習網路可以逼近任何函數,所以 f(x) 可以用一個深度學習網路來完成。在 NFM 裡,這個網路是以下這樣:
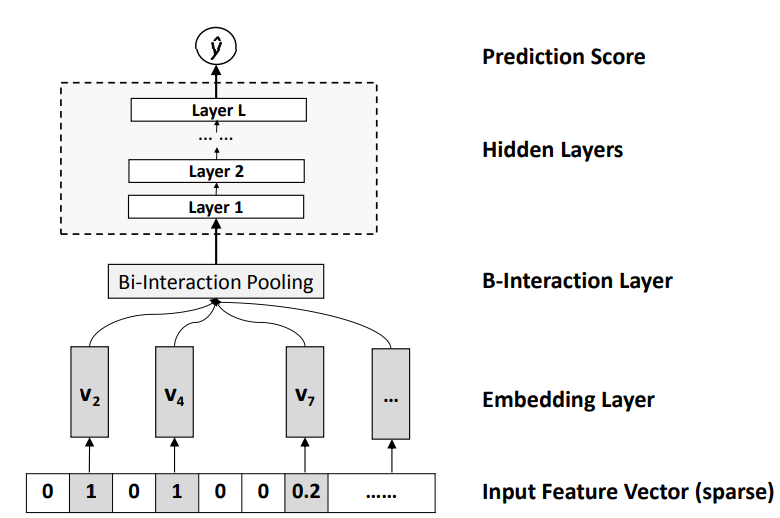
由圖可知,每個向量 xi 都會做embedding,最後得到 vi。
然後 這些 embedding 後的 k 維向量,就會進到 Bi-interaction Pooling 裡,做特徵交叉。
NFM 的作者定義 Bi-interaction Pooling 用以下式子來做:
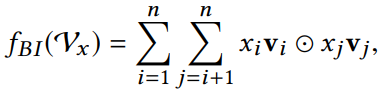
白話文說明就是,把每個非0的特徵將它和embedding相乘後,得到 k 維向量,再把所有的向量兩兩做元素積操作(element-wise product)。
什麼是向量的元素積呢?就是把兩個相同維度的向量,將他們對應的維度相乘,最後還是得到相同維度的向量,這就是元素積。
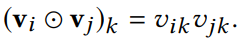
當上面說到兩兩做元素積操作的向量都拿到後,就把它們全部加起來,這就成為 Bi-interaction Pooling 的輸入,之後再接多個全連接層處理。
NFM 可以想成底層是FM,上層是DNN,若說 Deep&Wide 架構是併聯的話,那 NFM 就是一種串連架構。
這串連架構中間用了 Bi-interaction Pooling ,使得兩個網路變成一個整體,可以以完整的正向和反向傳播訓練,這樣才可以利用 FM 的Wide 的記憶力,又可以用到 DNN 的Deep優勢。
NFM 原始論文: Neural Factorization Machines for Sparse Predictive Analytics

